

We don’t wait for a new software release to update and improve - we want you to have the best version as soon as it’s ready and here to help you.
Summer 2021 updates
On 11th June 2021, we launched a series of improvements to our logic test. Here we detail what the improvements are, why they matter, and what you’ll notice (spoiler alert - they’re mostly under the hood, but still very cool!)
Increased statistical reliability
We are incredibly proud that we can announce an increase in average reliability from 0.86 to 0.94 for the logic test.
What this means is that our ability to give recruiters accurate information about candidates and talent pools was already great - and now we know that the information is even better.
Meaning?
Those who didn’t make a shortlist would not have made the shortlist, even with these changes.
When you receive your shortlists, in the short term, you’re not likely to see a huge change. However, long term, we expect that we will continue to learn, with greater accuracy, which traits are the best fit for each role.
For the data nerds 🤓
The correlation between the current and updated results is r=0.995, indicating a strong correspondence. Scientifically speaking, this means that construct validity remains excellent according to European standards.
What this means for you
- 76.1% of all Alva’s users will keep the same result
- 99.9% of Alva’s users will keep a result within +/- 1 point.
These small changes mostly affect candidates at either end of the distribution. Candidates with a current result above the average score are more likely to get a lower updated result, and those with a result below average are more likely to get a higher updated result.
Meaning?
Say a candidate logs back in to Alva to review their profile - like the 15% of our users who use their profile to efficiently apply to additional roles. If they were at the lower or higher end of the distribution, they might see a small tweak. In the vast majority of cases, this won’t affect who made the shortlist.
How will Role Fit be affected?
Mostly, it won’t, or it will be a minimal change. In jobs where the logic test is given more importance - say, in a role for an accountant rather than for a designer/line packer - recruiters might notice a change in the types of candidates who are shortlisted.
For the data nerds 🤓
The average change in Role Fit score is negligible (0.007 points). 88.3% of candidates will change less than 5 percentage points and 93.2% will change less than 15 percentage points.
The new ranking of candidates based on role fit will be very close or identical to the current ranking. 82.1% of candidate rankings will be unaffected, and those that are affected will display no visible change.
Change in Role Fit score after the updates to the logic test:
- 93.3% of candidates will keep the same label (i.e. Very high, High, Medium, Low and Very low).
- 4.8% will get a label that is one step lower than the current one and 1.9% will get a label that is one step higher.
Item bank updates
We have added 16 new tasks to our logic test item bank, which increases our ability to target candidates with an average level of logical ability, and a higher than average level.
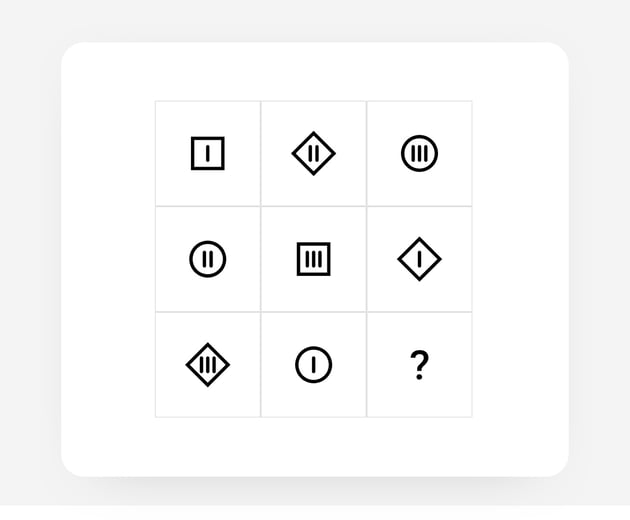
Why?
Data gathered from 77, 237 tests and 1.54 million responses gathered from 2019-2021 naturally gave us greater insight into the way our logic test functions.
So we applied those learnings to bring you the best results for everyone.
You’ll see
These changes aren’t easily visible to recruiters, but they will help us to work out your most ideal shortlist.
Meaning?
When you receive your shortlist of top candidates, in the short term, you’re not likely to see a huge change. However, long term, we will continue to make improvements to our tests to make sure that they are most likely to give you the best results.
Task retirement
We’ve retired two tasks because they have a lower correlation with logical ability than we expected. This means that they weren’t giving you the information that you need to make good decisions.
Why?
Alva uses Item Response Theory, rather than Classical Test Theory; this sets us apart from other psychometric providers, in both the test and the scoring of the test. One of the reasons why we use IRT is because we can remove items that aren’t holding their weight. If they aren’t holding their weight, they are wasting your time and your candidate’s time - and that’s not okay with us.
We set high standards for every part of the Alva process, continuously monitoring the performance of every item. We’re not afraid to make changes to make sure that everyone’s time is well spent.
So, we removed them!
You’ll notice
Over time you will notice a gradual improvement in the shortlists, and candidates will enjoy a better experience.
Guessing parameter
Item Response Theory allows candidates to answer the most appropriate questions. This is known to be the most accurate system in psychometric testing because candidates are already delivered tasks that match their ability.
Why?
The guessing parameter exists to deal with candidates who might make a best guess at an answer - and they’re guessing because they don’t know the answer.
Our data indicate that, because candidates are being delivered tasks that match their logical ability, they aren’t guessing! This makes the parameter redundant - and therefore a poor use of bandwidth.
You’ll notice
The only thing you might notice is a small change in results from the logic test (small difference = no more than 1 point on our scale).
From item-specific to global discrimination parameter
Some of our amazing tasks rarely get in front of candidates! This is because the algorithm that is used to select items hasn’t read them as being valid for that individual candidate. This is caused by small differences in the discrimination or scale parameter - nothing to do with the candidate’s background. Rather, it refers to how strongly items correlate with logical ability.
![]()
Using an item specific parameter makes our item selection algorithm skip some items - which simply means that the instructions in our algorithm is missing some amazing tasks!
Why?
Using a global discrimination parameter solves the problem in two ways. First, when all tasks share the same value, there will be a more even distribution of tasks, and more candidates will get to see them and enjoy them! Second, we now have another tool for monitoring and assessing the quality of our tasks. If we observe that a task doesn’t match the global discrimination parameter we will remove it from the test.
The logic of selecting items by level of difficulty relative to the candidate’s ability stays the same, ensuring that every item on our platform meets our standard for reliable and evidence-based estimation of logical ability.
For the data nerds 🤓
For the data lovers out there, this means that we are now using the 1PL model rather than the 3PL model. For the data-curious, that means that we’re using a more robust model, addressing a potential issue with under-identifiability in the 3PL model and lowering the risk of overfit.
Our ambition is to bring you the very best of emerging science and the best fit of candidates, using the most up-to-date insights and learnings.
You’ll notice
Candidates will experience tasks from a wider bank and should find the experience even more rewarding, learning more about themselves and reflecting well on the recruiters.
Most of these updates aren’t shiny! Why bother?
Even though you won’t notice every little amend, at Alva we want to ensure that we are always at the emerging edge of psychometrics, data science and machine learning. Every person on the team is committed to improving their knowledge and making it work for you.
At Alva, we started out with a best-in-class logic test, powered by best practices in machine learning and modern test theory. We are agile in the way we develop and iterate on our tests.
So even though these changes don’t reflect shiny new animations or activities, we want you to know that Alva’s tests will always help you to stay ahead of the curve.





